用差不多两个下午的时间读了这本120页的小册子,Andrew NG的诚意之作,并不是tutorial之类的巨头,而是娓娓道来的经验之谈,重点讨论了如何处理数据,如何判断算法哪里需要改进和如何分析错误三大块内容。读了一遍以后,自感只收获了不到一成,但仍可以写一篇小的杂记,以便后来查阅。
数据处理
- 数据集可以分为训练集(training set),开发集(dev set/validation set)和测试集(test set). 开发集主要用来调节参数和改变学习算法,测试集主要用来评估性能。开发集不是必须的。训练集/测试集往往 70% / 30%,如果有开发集的话可以划分为 70% / 15% / 15%。 训练集可以取自不同来源,而开发集和测试集应该尽可能的符合处理问题的实际分布,开发集和测试集应当符合同一分布。
- 开发集的规模应当在1000 ~ 10000个之间为佳。样本太小可能导致无法收敛,或者无法观察到细微的提升。
- 使用单一指标评估算法。常用的包含准确度(precision)和召回率(recall),两者呈负相关。可以采用F1 score来结合两者。
误差分析
- 可以将开发集分为eyeball数据集和blackbox数据集,如从5000张图片里随机抽取500张来成为eyeball数据集。 开发者要人工检查eyeball数据集,将分类错误的数据挑出来,分析错误原因,所以eyeball数据集不能太大。 剩下的blackbox数据集用来作为 调整算法后观察是否提升的数据集。
- bias和variance是错误率的两大指标。bias是分类器在训练集上的错误率,而variance代表在测试集或者开发集上,分类算法表现得比在训练集上差的多少。 也就是所,理想的总错误率通常等于bias + variance.
- overfitting,过拟合,在训练集上的bias非常低,但是variance很高,也即训练误差低,测试误差高,泛化能力不足。
- underfitting, 拟合不足,训练集上错误率高,测试集和训练集的错误差不多,代表训练不够,应当提高学习率,再加点epoches。
- overfitting + underfitting。 训练集上表现很差,测试集上表现更差。重新调节算法吧。
- 训练时,往往需要寻找一个最优错误率。可以从当前的state of art的论文里找到,也可以人工盲测估计。对于二分类之类简单问题,可以乐观的估计,最优错误率为0。由此可以把bias再度细分,分为avoidable bias(当前算法离最优秀算法的差距),和unavoidable bias(最优秀算法的误差)。 如果当前的bias已经开始接近不可避免误差了,通常是一个过拟合的信号。
- (重要)如果可避免误差比较高,那么说明当前算法离最优秀的算法还有很大差距,这个时候应当加大网络。如果variance比较高,说明模型泛化能力不足,应当加样本。
诊断学习过程
-
可以根据错误率曲线来分析什么时候该调参,什么时候该加样本。
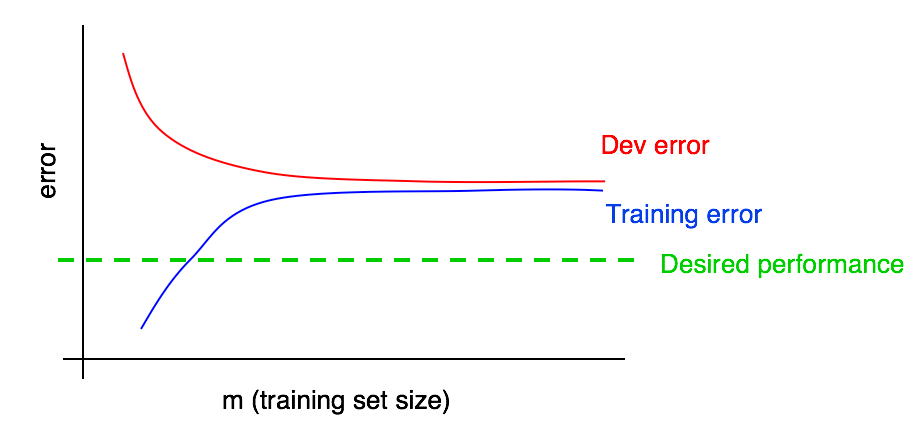 绿色的为理想的算法误差,蓝色的为训练误差。加入更多的样本通常会导致训练误差逐渐升高,当训练误差已经超过了理想的误差的时候,加入更多的样本只会让事情变得更糟糕。
绿色的为理想的算法误差,蓝色的为训练误差。加入更多的样本通常会导致训练误差逐渐升高,当训练误差已经超过了理想的误差的时候,加入更多的样本只会让事情变得更糟糕。 -
调参信号
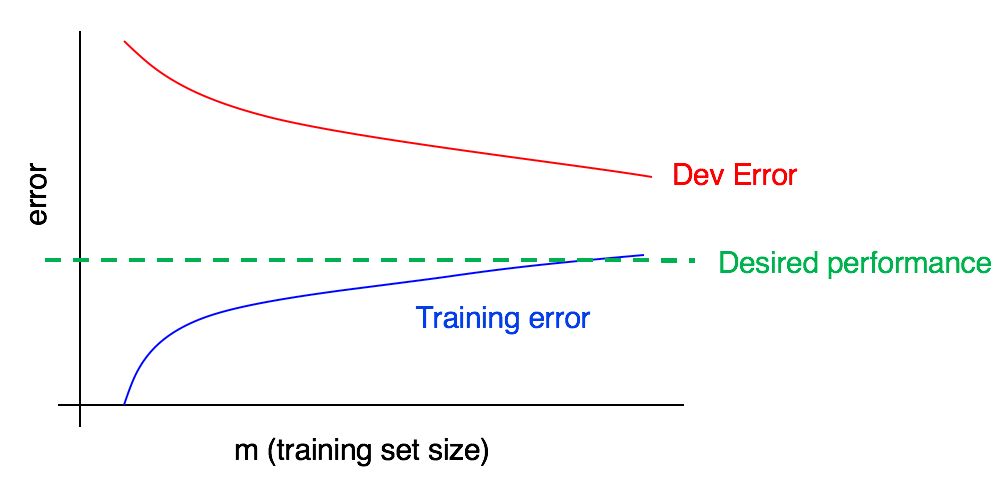 开发集的误差离训练集的误差还比较大,代表模型泛化能力不够。可以适度加样本,或者加入其他可以帮助提升泛化能力(如图像增强)的方式。
开发集的误差离训练集的误差还比较大,代表模型泛化能力不够。可以适度加样本,或者加入其他可以帮助提升泛化能力(如图像增强)的方式。
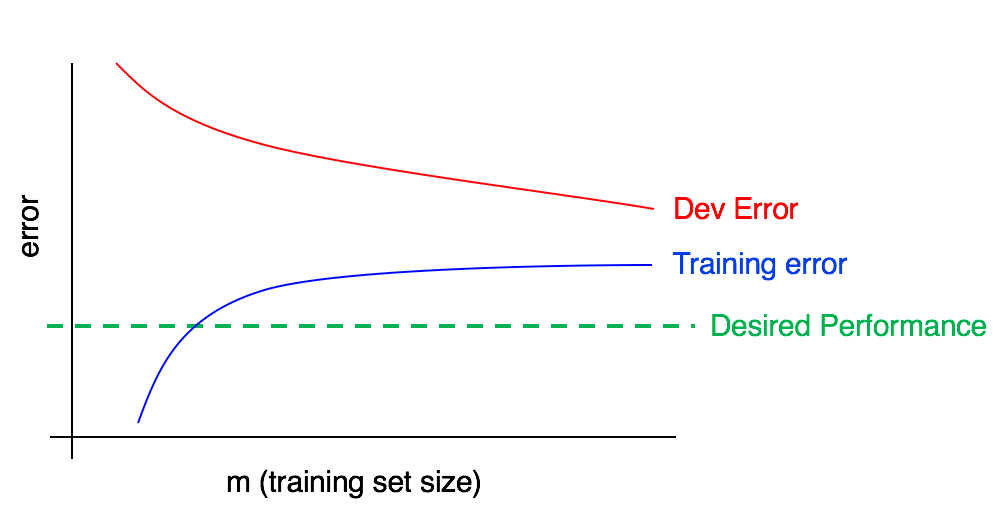 开发集和训练集的误差比较接近,而训练集的误差已经超过了理想的误差,代表算法还不够优秀,加大网络或者优化网络,可能会收获更好的效果。
开发集和训练集的误差比较接近,而训练集的误差已经超过了理想的误差,代表算法还不够优秀,加大网络或者优化网络,可能会收获更好的效果。
端对端学习
端对端学习可能需求更多的数据,而且往往更难以收集。使用管线的方式将任务分解为不同的stage,分别应用不同的算法来解决,对数据的需求量要小很多。