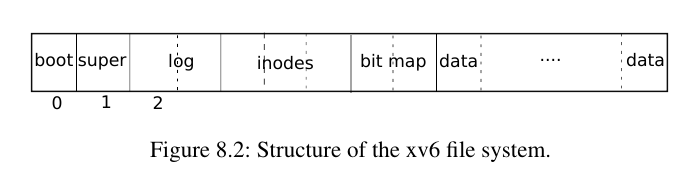
xv6的文件系统大概介于ext2和ext3之间吧,相较于ext2增加了日志(logging)部分,可以确保异常中断下下次重启硬盘可以恢复未写入的数据,
相较于真实的文件系统,xv6的文件系统采用朴素的线性结构而不是真实场景中的B+树来维持磁盘索引,查找文件是O(n)复杂度。
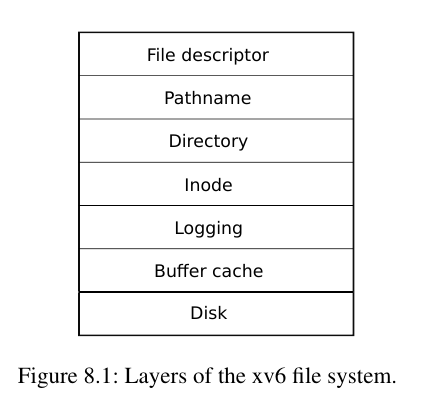
xv6的文件系统呈现层状的结构(与网络协议的结构类似),进程需要从最顶层的fd查找到最底层,并且底层的inode,cache等结构对应用程序是完全透明的,其中比较重要的是buffer-cache层和logging层。
buffer层
其实buffer层没什么特别好说的,一个环状的链表,维持一个固定的head入口,每个被更新的块会被插到链表的head->next,每次查找最不常使用的块只需要查找head->prev就可以了。因为根据程序的局部性,如果一个块被访问了,那么接下来重复访问它和它周围数据的几率会比较大。
// 每个数据块要维持引用计数,valid标志
struct buf {
int valid; // has data been read from disk?
int disk; // does disk "own" buf?
uint dev;
uint blockno;
struct sleeplock lock;
uint refcnt;
struct buf *prev; // LRU cache list
struct buf *next;
uchar data[BSIZE];
};
//链表的数据结构
struct {
struct spinlock lock;
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
struct buf head;
} bcache;
logging层
为什么我们需要logging层:因为操作磁盘上的数据并不是一个原子操作,而且是一个相当费时的操作,并且处理不好会有严重的安全危险。 假如系统在删除文件的过程中断电了,a文件inode指向一个已经被回收的硬盘块。我们再建立一个b文件,分配了被回收的硬盘块。那么我们可以访问a文件,实际上却读取的是b文件的内容!这里的原因是,回收硬盘块和回收inode两个操作并不是原子的。
logging层其实像是一个在硬盘上的缓存。xv6并不能直接操作硬盘上的数据和数据结构,而是将所有的操作变更登记到一个logging的区域,并通过一个commit函数将所有logging区域的操作复制到磁盘的数据结构上。
- 如果在commit中途断电了,那么下次开机的时候可以重新commit变更。
- 如果在commit之前断电了,被污染的只有logging区域,实际上硬盘的数据并不会受损。如果logging区域有数据,那么执行恢复操作。如果logging数据不完整(虽然有数据但是header的信息是错误的),那么logging当做是空的(断电前执行的更改被丢失了)。
static void
commit()
{
if (log.lh.n > 0) {
//把所有修改后的操作写入到log块中(注意:log是实际在硬盘上存在的区域)
write_log(); // Write modified blocks from cache to log
//在这一步之前崩溃,所有的log块的写入会丢失
//把log块(内存)的元信息写入log块(disk)上
write_head(); // Write header to disk -- the real commit
//复制log中所有数据到实际的区域
install_trans(0); // Now install writes to home locations
//在这一步之前崩溃,下次开机会重新复制log块的信息
//清空内存中log块元信息的数据信息
log.lh.n = 0;
//重新更新硬盘上的log块数据
write_head(); // Erase the transaction from the log
}
}