笔记栏文章声明
Warning
笔记栏所记录文章往往未经校对,或包含错误认识或偏颇观点,亦或采用只有自身能够理解的记录。
Info
Engine Version: 4.26.2
看代码之前列了一些问题,总结在这里: ISM的剔除逻辑/ISM的LOD计算过程: 结论: ISM大量复用了SM的逻辑,剔除/LOD计算都用的SM的逻辑,由于ISM可能会被大量摆放,其Bounds可能很大,其LOD可能得到一个很差的结果,大概率长期保持LOD0~1。
ISM的Instances的Buffers存在哪里在:
存在FStaticMeshInstanceBuffer这个结构体上,这个结构体在FInstancedStaticMeshSceneProxy->FInstancedStaticMeshRenderData->PerInstanceRenderData->InstanceBuffer
ISM的TransformBuffer默认精度为Half4,如何转成FP32
https://gist.github.com/BlurryLight/28852a23ca793185778bdf3b3172c32b
是否应该使用ISM组件?
结论: 该组件在LOD/剔除计算上存在缺陷,比较鸡肋,小规模用用可以,大规模用HISM。
ISM组件
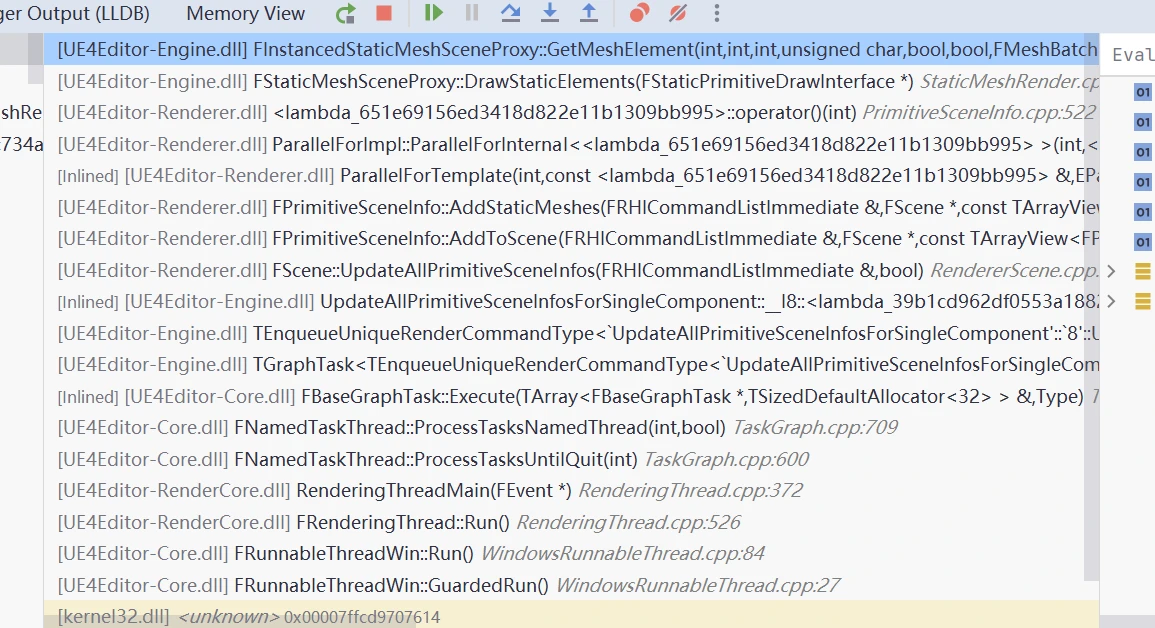
ISM渲染时候的堆栈是这样,一般情况下一个ISM的MeshProxy是StaticRelevance状态(在编辑器下打开unlit等视图(IsRichView)的情况下可能会走DynamicRelevance).
DynamicRelevance:GetDynamicMeshElements
StaticRelevance: FStaticMeshSceneProxy::DrawStaticElements
不过大体上,最后都会调用到FInstancedStaticMeshSceneProxy::GetMeshElement
ISM LOD的计算过程
只要有一个实例渲染,那么提交的drawcall都是整体的实例数量
ISM实际上是用的StaticMesh的LOD计算流程,只是在
- 提交FMeshBach的时候把
NumInstances从1设置为了NumInstances - 提交的InstancedLODIndex = LODIndex
void FInstancedStaticMeshSceneProxy::SetupInstancedMeshBatch(int32 LODIndex, int32 BatchIndex, FMeshBatch& OutMeshBatch) const
{
OutMeshBatch.VertexFactory = &InstancedRenderData.VertexFactories[LODIndex];
const uint32 NumInstances = InstancedRenderData.PerInstanceRenderData->InstanceBuffer.GetNumInstances();
FMeshBatchElement& BatchElement0 = OutMeshBatch.Elements[0];
BatchElement0.UserData = (void*)&UserData_AllInstances;
BatchElement0.bUserDataIsColorVertexBuffer = false;
BatchElement0.InstancedLODIndex = LODIndex;
BatchElement0.UserIndex = 0;
BatchElement0.PrimitiveUniformBuffer = GetUniformBuffer();
BatchElement0.NumInstances = NumInstances; // 提交的NumInstances == InstanceBuffer.GetNumInstances()
}
整体都要通过一个drawcall渲染,所以LOD都是统一的,一次drawcall只能渲染一个LOD
DrawStaticElements
在运行期更多还是走这个,ISM本身是不会走GetDynamicMeshElements的,只有在编辑器下打开unlit等视图(IsRichView)的情况下可能会走DynamicRelevance,这个时候会走GetDynamicMeshElements。
DrawStaticMeshElements 用的主要还是StaticMeshRender的逻辑
- 这里做了一些删节
- 删除了RVT有关的
- 删除了Editor有关的
主要有两个分支:
- 在有ForcedLOD的情况(这个ForceLOD不是cvar那个,是在StaticMeshEditor设上去的), 只绘制forceLOD的那个即可
- 没有ForcedLOD的情况,会有的LOD都要绘制,后续LOD选择的计算流程在
FRelevancePacket::MarkRelevant的ComputeLODForMeshes调用中,通过bounds/screensize来计算LOD等级
中间有一段关于Prez和Shadow的优化:
- 如果材质满足要求,不是Moveable,没有WPO等情况,那么可以走到
GetShadowMeshElement这个分支里去 - 如果不满足要求,纳闷就得老老实实的逐Section画
关闭优化: 绘制ShadowMap时候,多Section的Mesh被发起了两次Drawcall
 打开优化:绘制SHadow的时候Section被合并到一个Mesh上
打开优化:绘制SHadow的时候Section被合并到一个Mesh上
DrawStaticElements的实现
void FStaticMeshSceneProxy::DrawStaticElements(FStaticPrimitiveDrawInterface* PDI)
{
if (!HasViewDependentDPG())
{
// Determine the DPG the primitive should be drawn in.
uint8 PrimitiveDPG = GetStaticDepthPriorityGroup();
int32 NumLODs = RenderData->LODResources.Num();
//Never use the dynamic path in this path, because only unselected elements will use DrawStaticElements
bool bIsMeshElementSelected = false;
const auto FeatureLevel = GetScene().GetFeatureLevel();
const int32 NumRuntimeVirtualTextureTypes = RuntimeVirtualTextureMaterialTypes.Num();
//check if a LOD is being forced
if (ForcedLodModel > 0)
{
int32 LODIndex = FMath::Clamp(ForcedLodModel, ClampedMinLOD + 1, NumLODs) - 1;
const FStaticMeshLODResources& LODModel = RenderData->LODResources[LODIndex];
// Draw the static mesh elements.
for(int32 SectionIndex = 0; SectionIndex < LODModel.Sections.Num(); SectionIndex++)
{
const int32 NumBatches = GetNumMeshBatches();
PDI->ReserveMemoryForMeshes(NumBatches * (1 + NumRuntimeVirtualTextureTypes));
for (int32 BatchIndex = 0; BatchIndex < NumBatches; BatchIndex++)
{
FMeshBatch BaseMeshBatch;
if (GetMeshElement(LODIndex, BatchIndex, SectionIndex, PrimitiveDPG, bIsMeshElementSelected, true, BaseMeshBatch))
{
//RVT....
{
PDI->DrawMesh(BaseMeshBatch, FLT_MAX);
}
}
}
}
}
else //no LOD is being forced, submit them all with appropriate cull distances
{
for(int32 LODIndex = ClampedMinLOD; LODIndex < NumLODs; LODIndex++)
{
const FStaticMeshLODResources& LODModel = RenderData->LODResources[LODIndex];
float ScreenSize = GetScreenSize(LODIndex);
bool bUseUnifiedMeshForShadow = false;
bool bUseUnifiedMeshForDepth = false;
if (GUseShadowIndexBuffer && LODModel.bHasDepthOnlyIndices)
{
const FLODInfo& ProxyLODInfo = LODs[LODIndex];
// The shadow-only mesh can be used only if all elements cast shadows and use opaque materials with no vertex modification.
// In some cases (e.g. LPV) we don't want the optimization
bool bSafeToUseUnifiedMesh = AllowShadowOnlyMesh(FeatureLevel);
bool bAnySectionUsesDitheredLODTransition = false;
bool bAllSectionsUseDitheredLODTransition = true;
bool bIsMovable = IsMovable();
bool bAllSectionsCastShadow = bCastShadow;
for (int32 SectionIndex = 0; bSafeToUseUnifiedMesh && SectionIndex < LODModel.Sections.Num(); SectionIndex++)
{
const FMaterial* Material = ProxyLODInfo.Sections[SectionIndex].Material->GetRenderProxy()->GetMaterial(FeatureLevel);
// no support for stateless dithered LOD transitions for movable meshes
bAnySectionUsesDitheredLODTransition = bAnySectionUsesDitheredLODTransition || (!bIsMovable && Material->IsDitheredLODTransition());
bAllSectionsUseDitheredLODTransition = bAllSectionsUseDitheredLODTransition && (!bIsMovable && Material->IsDitheredLODTransition());
const FStaticMeshSection& Section = LODModel.Sections[SectionIndex];
bSafeToUseUnifiedMesh =
!(bAnySectionUsesDitheredLODTransition && !bAllSectionsUseDitheredLODTransition) // can't use a single section if they are not homogeneous
&& Material->WritesEveryPixel()
&& !Material->IsTwoSided()
&& !IsTranslucentBlendMode(Material->GetBlendMode())
&& !Material->MaterialModifiesMeshPosition_RenderThread() // 注意,这里不能有WPO
&& Material->GetMaterialDomain() == MD_Surface
&& !Material->IsSky()
&& !Material->GetShadingModels().HasShadingModel(MSM_SingleLayerWater);
bAllSectionsCastShadow &= Section.bCastShadow;
}
if (bSafeToUseUnifiedMesh)
{
bUseUnifiedMeshForShadow = bAllSectionsCastShadow;
// Depth pass is only used for deferred renderer. The other conditions are meant to match the logic in FDepthPassMeshProcessor::AddMeshBatch.
bUseUnifiedMeshForDepth = ShouldUseAsOccluder() && GetScene().GetShadingPath() == EShadingPath::Deferred && !IsMovable();
if (bUseUnifiedMeshForShadow || bUseUnifiedMeshForDepth)
{
const int32 NumBatches = GetNumMeshBatches();
PDI->ReserveMemoryForMeshes(NumBatches);
for (int32 BatchIndex = 0; BatchIndex < NumBatches; BatchIndex++)
{
FMeshBatch MeshBatch;
if (GetShadowMeshElement(LODIndex, BatchIndex, PrimitiveDPG, MeshBatch, bAllSectionsUseDitheredLODTransition))
{
bUseUnifiedMeshForShadow = bAllSectionsCastShadow;
MeshBatch.CastShadow = bUseUnifiedMeshForShadow;
MeshBatch.bUseForDepthPass = bUseUnifiedMeshForDepth;
MeshBatch.bUseAsOccluder = bUseUnifiedMeshForDepth;
MeshBatch.bUseForMaterial = false;
PDI->DrawMesh(MeshBatch, ScreenSize);
}
}
}
}
}
// Draw the static mesh elements.
for(int32 SectionIndex = 0;SectionIndex < LODModel.Sections.Num();SectionIndex++)
{
const int32 NumBatches = GetNumMeshBatches();
PDI->ReserveMemoryForMeshes(NumBatches * (1 + NumRuntimeVirtualTextureTypes));
for (int32 BatchIndex = 0; BatchIndex < NumBatches; BatchIndex++)
{
FMeshBatch BaseMeshBatch;
if (GetMeshElement(LODIndex, BatchIndex, SectionIndex, PrimitiveDPG, bIsMeshElementSelected, true, BaseMeshBatch))
{
//.. remove rtv code
{
// Standard mesh elements.
// If we have submitted an optimized shadow-only mesh, remaining mesh elements must not cast shadows.
// 如果前面已经进入过`GetShadowMeshElement`这个分支,那么这里就不需要投射阴影了
// 如果前面没有,那么这里画每个Section的时候就得投射阴影..
FMeshBatch MeshBatch(BaseMeshBatch);
MeshBatch.CastShadow &= !bUseUnifiedMeshForShadow;
MeshBatch.bUseAsOccluder &= !bUseUnifiedMeshForDepth;
MeshBatch.bUseForDepthPass &= !bUseUnifiedMeshForDepth;
PDI->DrawMesh(MeshBatch, ScreenSize);
}
}
}
}
}
}
}
}
DynamicMeshElements
如果走到编辑器下GetDynamicMeshElements里,简化代码如下
void FInstancedStaticMeshSceneProxy::GetDynamicMeshElements(const TArray<const FSceneView*>& Views, const FSceneViewFamily& ViewFamily, uint32 VisibilityMap, FMeshElementCollector& Collector) const
{
for (int32 ViewIndex = 0; ViewIndex < Views.Num(); ViewIndex++)
{
if (VisibilityMap & (1 << ViewIndex))
{
const FSceneView* View = Views[ViewIndex];
// 计算当前组件的LOD等级,受r.ForceLOD影响
const int32 LODIndex = GetLOD(View);
// 获取到LOD等级后,取出属于该LOD的顶点数据,通过GetMeshElement构建drawcall
const FStaticMeshLODResources& LODModel = StaticMesh->RenderData->LODResources[LODIndex];
for (int32 SectionIndex = 0; SectionIndex < LODModel.Sections.Num(); SectionIndex++)
{
const int32 NumBatches = GetNumMeshBatches();
for (int32 BatchIndex = 0; BatchIndex < NumBatches; BatchIndex++)
{
FMeshBatch& MeshElement = Collector.AllocateMesh();
if (GetMeshElement(LODIndex, BatchIndex, SectionIndex, GetDepthPriorityGroup(View), BatchRenderSelection[SelectionGroupIndex],
...
通过GetLOD函数获取Lod等级,该函数没有覆写,直接转发到StaticMesh上,通过Bounds计算ScreenSize来计算LOD。
InstanceSM重写了CalcBounds,会计算所有Bounds的总和。
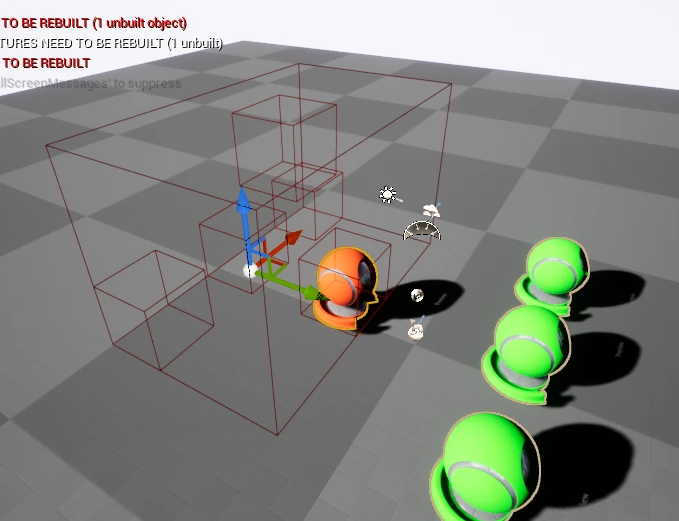
这有一个致命问题,这会导致计算的LOD等级偏大。 比如如下图,故意摆了一个离其他物体很远的物体。这会导致Bounds计算偏大,而整体用很大的LOD等级渲染(注意看背后的HISM组件已经切到了很小的LOD等级)

ISM的InstancesBuffers的管理(UE4.26)
UE5的话是走GPUScene感觉不太一样..
CPU端
CPU端的数据在UInstancedStaticMeshComponent里,简化代码如下,这些属性都是UPROPERTY,可以从编辑器里看到
class ENGINE_API UInstancedStaticMeshComponent : public UStaticMeshComponent{
/** Array of instances, bulk serialized. */
UPROPERTY(EditAnywhere, SkipSerialization, DisplayName="Instances", Category=Instances, meta=(MakeEditWidget=true, EditFixedOrder))
TArray<FInstancedStaticMeshInstanceData> PerInstanceSMData;
/** Defines the number of floats that will be available per instance for custom data */
UPROPERTY(EditAnywhere, Category=Instances, AdvancedDisplay)
int32 NumCustomDataFloats;
/** Array of custom data for instances. This will contains NumCustomDataFloats*InstanceCount entries. The entries are represented sequantially, in instance order. Can be read in a material and manipulated through Blueprints.
* Example: If NumCustomDataFloats is 1, then each entry will belong to an instance. Custom data 0 will belong to Instance 0. Custom data 1 will belong to Instance 1 etc.
* Example: If NumCustomDataFloats is 2, then each pair of sequential entries belong to an instance. Custom data 0 and 1 will belong to Instance 0. Custom data 2 and 3 will belong to Instance 2 etc.
*/
UPROPERTY(EditAnywhere, EditFixedSize, SkipSerialization, DisplayName="Custom data", Category=Instances, AdvancedDisplay, meta=(EditFixedOrder))
TArray<float> PerInstanceSMCustomData;
CPU端到GPU端的更新
这块代码的入口可以从编辑器相关的代码进去,我们在Details面板编辑了Instances属性,肯定会触发CPU-GPU的数据更新

注意: UE5打开GPUScene以后,有点不一样,这里只分析UE4.26 其主要的套路是:
- InstanceUpdateCmdBuffer.Edit()
- MarkRenderStateDirty()
MarkRenderStateDirty会导致Proxy从Scene里删除又重新添加,最后会经过UInstancedStaticMeshComponent::CreateSceneProxy()
其中关于Buffer更新的关键代码在于
if (InstanceUpdateCmdBuffer.NumTotalCommands() != 0)
{
FlushInstanceUpdateCommands();
}
这个FlushInstanceUpdateCommands();函数是个假的。。我一开始以为这个函数会逐条执行里面记录的指令,增量更新buffer ,结果它直接Reset了所有指令,然后依靠CPU端的数据全量更新GPU端的数据
void UInstancedStaticMeshComponent::FlushInstanceUpdateCommands()
{
InstanceUpdateCmdBuffer.Reset();
FStaticMeshInstanceData RenderInstanceData = FStaticMeshInstanceData(GVertexElementTypeSupport.IsSupported(VET_Half2));
BuildRenderData(RenderInstanceData, PerInstanceRenderData->HitProxies);
PerInstanceRenderData->UpdateFromPreallocatedData(RenderInstanceData);
}
这个PerInstanceRenderData是个重点对象,它是UInstancedStaticMeshComponent的一个成员,类型是FInstancedStaticMeshRenderData,它的UpdateFromPreallocatedData函数会把CPU端的数据全量更新到GPU端
他在ISM BeginDestroy的时候销毁。
这个类实际不复杂,但是它是一个跨GameThread和RenderThread的对象,需要注意不要写出同步问题..
它的数据更新流程是:
- ISM组件调用BuildRenderData组装一个栈上的
FStaticMeshInstanceData对象 - 调用
UpdateFromPreallocatedData把栈上的数据拷贝到PerInstanceRenderData的InstanceBuffer里,里面是一个愚蠢的MemSwap函数,实际上用MemCpy就好 - 然后推送任务到RenderThread更新FStaticMeshInstanceBuffer
这里出现了若干数据结构:
- FPerInstanceRenderData: 辅助类,负责建立
FStaticMeshInstanceBuffer,并且在UpdateFromPreallocatedData里把CPU端的数据拷贝到FStaticMeshInstanceBuffer里 - FStaticMeshInstanceBuffer: RenderThread用的类,包括SRV等信息
- FStaticMeshInstanceData: CPU端用的类,包括CPU端的数据
struct FPerInstanceRenderData
{
// Should be always constructed on main thread
FPerInstanceRenderData(FStaticMeshInstanceData& Other, ERHIFeatureLevel::Type InFeaureLevel, bool InRequireCPUAccess);
~FPerInstanceRenderData();
/**
* Call to update the Instance buffer with pre allocated data without recreating the FPerInstanceRenderData
* @param InComponent - The owning component
* @param InOther - The Instance data to copy into our instance buffer
*/
ENGINE_API void UpdateFromPreallocatedData(FStaticMeshInstanceData& InOther);
/**
*/
ENGINE_API void UpdateFromCommandBuffer(FInstanceUpdateCmdBuffer& CmdBuffer);
/** Hit proxies for the instances */
TArray<TRefCountPtr<HHitProxy>> HitProxies;
/** cached per-instance resource size*/
SIZE_T ResourceSize;
/** Instance buffer */
FStaticMeshInstanceBuffer InstanceBuffer;
TSharedPtr<FStaticMeshInstanceData, ESPMode::ThreadSafe> InstanceBuffer_GameThread;
};
void FPerInstanceRenderData::UpdateFromPreallocatedData(FStaticMeshInstanceData& InOther)
{
InstanceBuffer.RequireCPUAccess = (InOther.GetOriginResourceArray()->GetAllowCPUAccess() || InOther.GetTransformResourceArray()->GetAllowCPUAccess() || InOther.GetLightMapResourceArray()->GetAllowCPUAccess()) ? true : InstanceBuffer.RequireCPUAccess;
ResourceSize = InstanceBuffer.RequireCPUAccess ? InOther.GetResourceSize() : 0;
InOther.SetAllowCPUAccess(InstanceBuffer.RequireCPUAccess);
InstanceBuffer_GameThread = MakeShared<FStaticMeshInstanceData, ESPMode::ThreadSafe>();
FMemory::Memswap(&InOther, InstanceBuffer_GameThread.Get(), sizeof(FStaticMeshInstanceData)); // 愚蠢的memswap,感觉用memcpy就可以了
typedef TSharedPtr<FStaticMeshInstanceData, ESPMode::ThreadSafe> FStaticMeshInstanceDataPtr;
FStaticMeshInstanceDataPtr InInstanceBufferDataPtr = InstanceBuffer_GameThread;
FStaticMeshInstanceBuffer* InInstanceBuffer = &InstanceBuffer;
ENQUEUE_RENDER_COMMAND(FInstanceBuffer_UpdateFromPreallocatedData)(
[InInstanceBufferDataPtr, InInstanceBuffer](FRHICommandListImmediate& RHICmdList)
{
InInstanceBuffer->InstanceData = InInstanceBufferDataPtr;
InInstanceBuffer->UpdateRHI(); // UpdateRHI = ReleaseRHI + InitRHI, 这里更新了它的InstanceData后,下一步就是在InitRHI里把数据传输到GPU上
}
);
}
FStaticMeshInstanceBuffer这个是个纯RenderThread的类了,他的所有成员函数都该在RenderThread上执行。
比如InitRHI,这里实际上在创建GPU端的数据,跟到CreateVertexBuffer里就可以看到RHICreateVertexBuffer了。
void FStaticMeshInstanceBuffer::InitRHI()
{
check(InstanceData);
if (InstanceData->GetNumInstances() > 0)
{
QUICK_SCOPE_CYCLE_COUNTER(STAT_FStaticMeshInstanceBuffer_InitRHI);
SCOPED_LOADTIMER(FStaticMeshInstanceBuffer_InitRHI);
LLM_SCOPE(ELLMTag::InstancedMesh);
auto AccessFlags = BUF_Static;
CreateVertexBuffer(InstanceData->GetOriginResourceArray(), AccessFlags | BUF_ShaderResource, 16, PF_A32B32G32R32F, InstanceOriginBuffer.VertexBufferRHI, InstanceOriginSRV);
CreateVertexBuffer(InstanceData->GetTransformResourceArray(), AccessFlags | BUF_ShaderResource, InstanceData->GetTranslationUsesHalfs() ? 8 : 16, InstanceData->GetTranslationUsesHalfs() ? PF_FloatRGBA : PF_A32B32G32R32F, InstanceTransformBuffer.VertexBufferRHI, InstanceTransformSRV);
CreateVertexBuffer(InstanceData->GetLightMapResourceArray(), AccessFlags | BUF_ShaderResource, 8, PF_R16G16B16A16_SNORM, InstanceLightmapBuffer.VertexBufferRHI, InstanceLightmapSRV);
if (InstanceData->GetNumCustomDataFloats() > 0)
{
CreateVertexBuffer(InstanceData->GetCustomDataResourceArray(), AccessFlags | BUF_ShaderResource, 4, PF_R32_FLOAT, InstanceCustomDataBuffer.VertexBufferRHI, InstanceCustomDataSRV);
// Make sure we still create custom data SRV on platforms that do not support/use MVF
if (InstanceCustomDataSRV == nullptr)
{
InstanceCustomDataSRV = RHICreateShaderResourceView(InstanceCustomDataBuffer.VertexBufferRHI, 4, PF_R32_FLOAT);
}
}
else
{
InstanceCustomDataSRV = GDummyFloatBuffer.ShaderResourceViewRHI;
}
}
}
ISM的组件 Transformation FP16的问题
对于一些大世界的情况,FP16的精度是不够的,从代码里可以看到FStaticMeshInstanceBuffer实际上是支持Fp16的,但是他用不用bHafl16取决于 InstanceData->GetTranslationUsesHalfs() 是否用half,而FStaticMeshInstanceData的构造函数太霸道了
FStaticMeshInstanceData(bool bInUseHalfFloat)
: bUseHalfFloat(PLATFORM_BUILTIN_VERTEX_HALF_FLOAT || bInUseHalfFloat) // 这里实际上应该是一个&&, PLATFORM_BUILTIN_VERTEX_HALF_FLOAT 对于绝大多数平台都应该是1,所以这里默认就用了16位。
这块可以看文章开头的Patch对引擎处理一下。
UE5的一些变化
UE5的FInstancedStaticMeshVertexFactory::InitRHI()多了这个,这些buffer不会被绑定上去。
if (!bCanUseGPUScene)
{
FInstancedStaticMeshVertexFactoryUniformShaderParameters UniformParameters;
UniformParameters.VertexFetch_InstanceOriginBuffer = GetInstanceOriginSRV();
UniformParameters.VertexFetch_InstanceTransformBuffer = GetInstanceTransformSRV();
UniformParameters.VertexFetch_InstanceLightmapBuffer = GetInstanceLightmapSRV();
UniformParameters.InstanceCustomDataBuffer = GetInstanceCustomDataSRV();
UniformParameters.NumCustomDataFloats = Data.NumCustomDataFloats;
UniformBuffer = TUniformBufferRef<FInstancedStaticMeshVertexFactoryUniformShaderParameters>::CreateUniformBufferImmediate(UniformParameters, UniformBuffer_MultiFrame, EUniformBufferValidation::None);
}
要在GPUScene上更新的话,除了暴力MarkRenderStateDirty,还有一个函数是MarkRenderInstancesDirty
void UInstancedStaticMeshComponent::SendRenderInstanceData_Concurrent()
{
Super::SendRenderInstanceData_Concurrent();
// If the primitive isn't hidden update its transform.
const bool bDetailModeAllowsRendering = DetailMode <= GetCachedScalabilityCVars().DetailMode;
if (InstanceUpdateCmdBuffer.NumTotalCommands() && bDetailModeAllowsRendering && (ShouldRender() || bCastHiddenShadow || bAffectIndirectLightingWhileHidden || bRayTracingFarField))
{
UpdateBounds();
// Update the scene infos transform for this primitive.
GetWorld()->Scene->UpdatePrimitiveInstances(this); // 关键是这里
InstanceUpdateCmdBuffer.Reset();
}
}
后面代码就复杂了,会走到GPUScnee里面去
HISM组件 细粒度剔除
HISM组件支持在每个leaf的粒度进行剔除
在打开RenderingFreeze的情况下,只露出一个球。
HISM组件可以剔除到只剩下一个球(一个球的顶点有3万多,所以一个leaf就是一个球)。
而ISM组件整体渲染。