What is Binning Pass?
Reference: Tile-based rendering
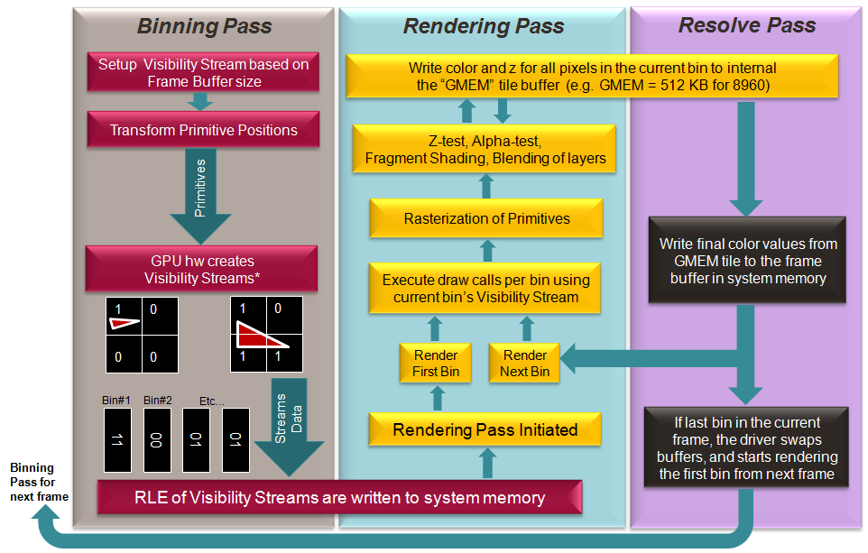
Binning Pass is a special vertex pass which marks which bin a triangle visible belongs to. It's a common tech widely used in Mobile GPU to reduce the amount of fragment shader invocations.
How is Binning Pass implemented?
I've been curious about it for a long time, especially when I ran into a performance issue(Snapdragon Profiler will show how long Binning Pass is) about it.
It is implemented in driver by the GPU vendor and not public. There are some text descriptions about it, but no real code.
Luckily, there is a reversed-engine driver named freedreno in Mesa which implements this feature.
I've taken some code snippets from freedreno ir3 driver as reference:
static inline bool
ir3_has_binning_vs(const struct ir3_shader_key *key)
{
if (key->tessellation || key->has_gs)
return false;
return true;
}
static bool
needs_binning_variant(struct ir3_shader_variant *v)
{
// if tessellation or geometry shader is enabled, we don't need binning pass
if ((v->type == MESA_SHADER_VERTEX) && ir3_has_binning_vs(&v->key))
return true;
return false;
}
static struct ir3_shader_variant *
create_variant(struct ir3_shader *shader, const struct ir3_shader_key *key,
bool write_disasm, void *mem_ctx)
{
... // judge if needs binning pass
if (needs_binning_variant(v)) {
v->binning = alloc_variant(shader, key, v, mem_ctx);
if (!v->binning)
goto fail;
v->binning->disasm_info.write_disasm = write_disasm;
}
...
// the actual work happens in `compile_variant``
if (needs_binning_variant(v) && !compile_variant(shader, v->binning))
goto fail;
...
}
When compiling a Vertex Shader it determines if a Binning Pass is required, if so it compiles an additional Binning Pass variant.
The actual conversion happens in
int
ir3_compile_shader_nir(struct ir3_compiler *compiler,
struct ir3_shader *shader,
struct ir3_shader_variant *so)
int ir3_compile_shader_nir(...)
{
/* at this point, for binning pass, throw away unneeded outputs: */
if (so->binning_pass && (ctx->compiler->gen < 6))
fixup_binning_pass(ctx, end);
}
Let's jump to fixup_binning_pass:
// https://www.khronos.org/opengl/wiki/Built-in_Variable_(GLSL)#Vertex_shader_outputs
// gl_Position
// gl_PointSize
// gl_ClipDistance[2]
// gl_ViewportIndex // GS output, need GL 4.1 or ARB_Viewport_array
static bool
output_slot_used_for_binning(gl_varying_slot slot)
{
return slot == VARYING_SLOT_POS || slot == VARYING_SLOT_PSIZ ||
slot == VARYING_SLOT_CLIP_DIST0 || slot == VARYING_SLOT_CLIP_DIST1 ||
slot == VARYING_SLOT_VIEWPORT;
}
static void
fixup_binning_pass(struct ir3_context *ctx, struct ir3_instruction *end)
{
struct ir3_shader_variant *so = ctx->so;
unsigned i, j;
/* first pass, remove unused outputs from the IR level outputs: */
for (i = 0, j = 0; i < end->srcs_count; i++) {
unsigned outidx = end->end.outidxs[i];
unsigned slot = so->outputs[outidx].slot;
if (output_slot_used_for_binning(slot)) {
end->srcs[j] = end->srcs[i];
end->end.outidxs[j] = end->end.outidxs[i];
j++;
}
}
end->srcs_count = j;
/* second pass, cleanup the unused slots in ir3_shader_variant::outputs
* table:
*/
for (i = 0, j = 0; i < so->outputs_count; i++) {
unsigned slot = so->outputs[i].slot;
if (output_slot_used_for_binning(slot)) {
so->outputs[j] = so->outputs[i];
/* fixup outidx to point to new output table entry: */
for (unsigned k = 0; k < end->srcs_count; k++) {
if (end->end.outidxs[k] == i) {
end->end.outidxs[k] = j;
break;
}
}
j++;
}
}
so->outputs_count = j;
}
It looks as if the Output variable, if not in a specific list(determined by output_slot_used_for_binning), is removed from the IL level and the Input/Output Indices of the Shader are re-updated.
I'm sure that in the subsequent processing of Shader IL, the calculations of those deleted Output variables are optimized away as dead code.
This gives a simplified version of VS, which is actually, the Binning Pass.
Easily we can get another deduction: if the VS does a lot sampling/computing with gl_Position, the Binning Pass may have similar cost as VS, making the calculation double.